
Google stopt met AJAX-crawling: heeft dit gevolgen?
Vorige maand publiceerde Google dat het Q2 2018 zal stoppen met het AJAX-crawling scheme voor indexatie van websites. Als je website er voor SEO-doeleinden gebruik van maakt, wil je het liefst controleren of alles correct staat om fluctuaties in organische posities te voorkomen. Wat is AJAX-crawling en hoe werkt het? Waarom kan het een gevaar zijn als Google de manier van crawlen van AJAX-applicaties verandert? En hoe kun je zelf controleren of jouw website een risico loopt? Je leest het allemaal in dit blog.
Wat is AJAX-crawling?
AJAX staat voor Asynchronous Javascript and XML. Het wordt gebruikt voor de ontwikkeling van interactieve webapplicaties. AJAX-crawling is een manier om webapplicatiepagina’s die afhankelijk zijn van Javascript, leesbaar te maken voor Google.
Zoekmachines waren oorspronkelijk goed in staat om statische elementen te crawlen en indexeren. Bij Javascript dat dynamische elementen aan webpagina’s kan toevoegen, was het laden en indexeren voor zoekmachines lastiger. Webapplicaties werken vaak met veel Javascript en op een manier dat webpagina’s niet leesbaar waren voor zoekmachines.
Voor SEO was dit een groot obstakel: er was minder content en dus context voor de zoekmachines om pagina’s op te beoordelen. Een plek hoog in de organische zoekresultaten was voor pagina’s met dynamische elementen niet haalbaar. Het AJAX-crawling scheme was de oplossing om deze pagina’s toch leesbaar en indexeerbaar te maken voor zoekmachines.
Hoe zorg je dat een zoekmachine toch kan lezen wat er op de webpagina staat?
Je kunt een webserver zo instellen dat een andere pagina aan de zoekmachine wordt getoond dan aan de bezoeker. De bezoeker krijgt dan de originele (van Javascript-afhankelijke) webpagina te zien. Zoekmachine bots krijgen een andere, statische variant van de pagina geserveerd. Dit zogenaamde HTML-snapshot bestaat uit HTML en CSS: goed voor zoekmachines te lezen én indexeren.
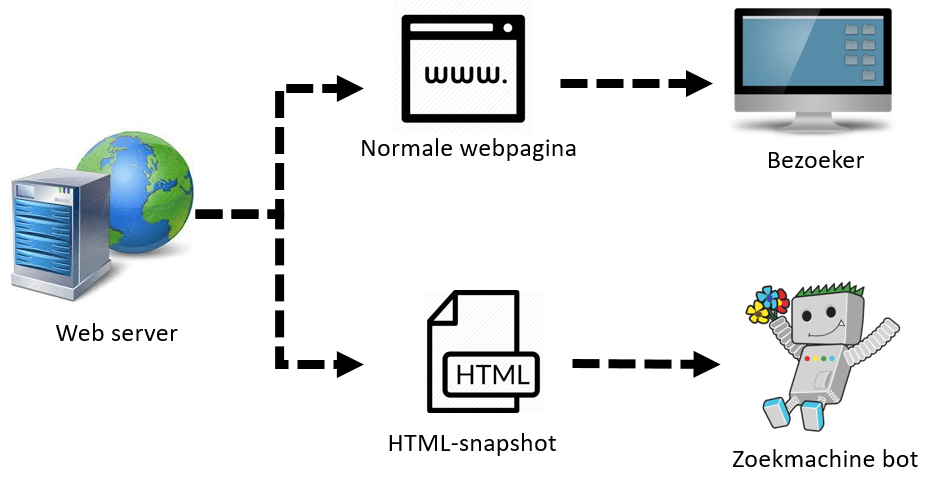
Hoe controleer je of een website gebruik maakt van HTML-snapshots?
Er zijn twee manieren om het gebruik van HTML-snapshots te herkennen:
- URL’s van de website bevatten van een zogenaamde hashbang-constructie (#!)
- In de broncode (CTRL + U) van de pagina staat de verwijzing: <meta name=”fragment” content=”!”>
Wanneer een zoekmachine één van bovenstaande situaties tegenkomt, dan zal hij het snapshot opvragen. Je kunt zelf de HTML-snapshots van je website bekijken:
- Hashbang-URL’s: Vervang in de URL de hashbang (#!) door: ?_escaped_fragment_=
- URL’s zonder hashbang (met meta fragment tag): Voeg de URL aan met ?_escaped_fragment_=

Aankondiging Google
In december 2017 heeft Google op het Webmastersblog aangekondigd dat ze in het tweede kwartaal van 2018 gaan stoppen met het ondersteunen van het originele AJAX-crawlingsysteem. Volgens Google is de Googlebot veel beter geworden in het crawlen van Javascript. Hierdoor worden de HTML-snapshots overbodig.
“With this change, Googlebot will render the #! URL directly, making it unnecessary for the website owner to provide a rendered version of the page.” – Google Webmaster Blog
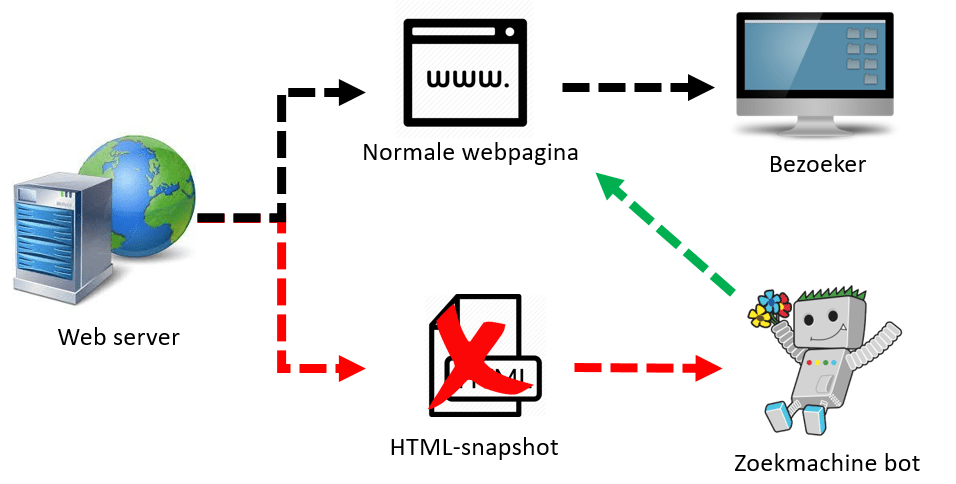
AJAX-crawling wordt al sinds 2015 afgekeurd door Google, omdat er een betere oplossing beschikbaar kwam. Ondanks dat ze de aanpak afkeurden, werd de ondersteuning nog voortgezet. Tot Q2 2018 zal Google de HTML-snapshots blijven gebruiken voor de indexatie van webpagina’s. Google heeft er vertrouwen genoeg in dat het werkt. Na de update verwacht Google geen significante verschillen in organische zoekresultaten.
Wat moet ik nu doen?
Zo nu en dan kom ik websites tegen die gebruik maken van HTML-snapshots. Na de update zal de Googlebot de webpagina direct gaan crawlen en het HTML-snapshot negeren. Op korte termijn hoeft er niet (per se) actie te worden ondernomen.
Bing, de andere “grote” zoekmachine, heeft nog niet dergelijk nieuws naar buiten gebracht. Ondanks dat het marktaandeel van Bing binnen Nederland niet heel hoog is (3-4% in 2017) wil je het organische verkeer afkomstig uit Bing niet zomaar verliezen. De werkwijze met HTML-snapshots wordt ook bij Bing afgeraden, maar ze ondersteunen de HTML-snapshots aanpak nog wel.
Is er een risico nu Google zijn werkwijze aanpast?
Het klinkt alsof er niet zoveel aan de hand is: Google zal het goed hebben getest de werkwijze niet zomaar aanpassen. Het risico ligt in dit geval ook niet bij Google.
Het gevaar ligt op de loer bij verschillen tussen de normale webpagina’s en de HTML-snapshots. Wanneer in de HTML-snapshots gegevens zijn gemarkeerd (structured data) en deze gegevens niet bij een normale webpagina staan, dan kun je de rich snippets na Q2 verliezen. Voor elementen als de paginatitel en metabeschrijving geldt dat verschillen tussen snapshot en webpagina na livegang van de manier van crawlen anders zijn dan voor de update toen de HTML-snapshots werden gebruikt voor indexatie. Dit kan fluctuaties en eventueel wegzakken in SEO-rankings als gevolg hebben. Dit wil je uiteraard voorkomen.
Hoe kan ik controleren op verschillen?
Je wilt uiteraard niet dat rankings wegvallen, rich snippets niet meer worden vertoond en vreemde metadata wordt getoond. Voer daarom een check uit. Google zal je via Search Console notificaties sturen voor websites/webpagina’s met potentiële problemen, maar een eigen controle kan geen kwaad.
Zo kun je Google Chrome bij ‘Inspecteren’ de verschillen tussen de normale webpagina en het HTML-snapshot controleren.
De acties die Google voorstelt:
- Zorg voor toegang tot Google Search Console. Tools om te testen bevinden zich hier en via deze weg stuurt Google eventueel meldingen.
- Gebruik de Fetch as Google tool in Search Console om uit te sluiten dat er zichtbare verschillen zijn tussen de variant die de gebruiker ziet en de variant die de Googlebot ziet. Bij de tool vul je de normale webpagina in.

- Check in Google Chrome via ‘Inspecteren’ of links een no-follow hebben waar dat nodig is. Bijvoorbeeld links in comments onder blogartikelen.
- Check paginatitels, metabeschrijvingen, robots, metatags en andere metadata via ‘Inspecteren’ in Google Chrome. Controleer ook of er structured data aanwezig is in het HTML-snapshot en de normale pagina. Dit moet overeenkomen.
- Controleer plug-in-based content. Als er Flash, Silverlight of andere op plug-in gebaseerde content aanwezig is, dan dient deze geconverteerd te worden naar Javascript om indexeerbaar te kunnen worden.
Indien er geen opvallende verschillen zijn te vinden, dan zou je je volgens Google geen zorgen hoeven te maken. Is dit wel het geval? Zijn er wel opvallende verschillen te zien? Dan adviseer ik je om de tafel te gaan zitten met de technische afdeling/partij. Je lost het bij voorkeur op voor Google daadwerkelijk anders gaat crawlen.
“Voorkomen is beter dan genezen.”
Succes!



